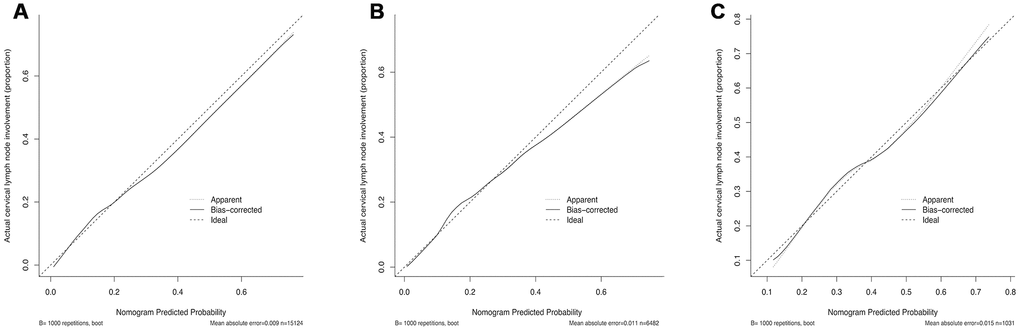
Figure 3.Calibration curves of the nomogram for predicting CRLNI in PTMC patients. (A) Calibration curve of the nomogram for training set. (B) Calibration curve of the nomogram for internal testing set. (C) Calibration curve of the nomogram for external testing set. The x-axis represents the predicted CRLNI. The y-axis represents the actual CRLNI. The diagonal dotted line stands for a perfect prediction using an ideal model. We drew the solid line to represent the performance of the nomogram, of which the closer fit to the diagonal dotted line represents the better prediction of the nomogram.