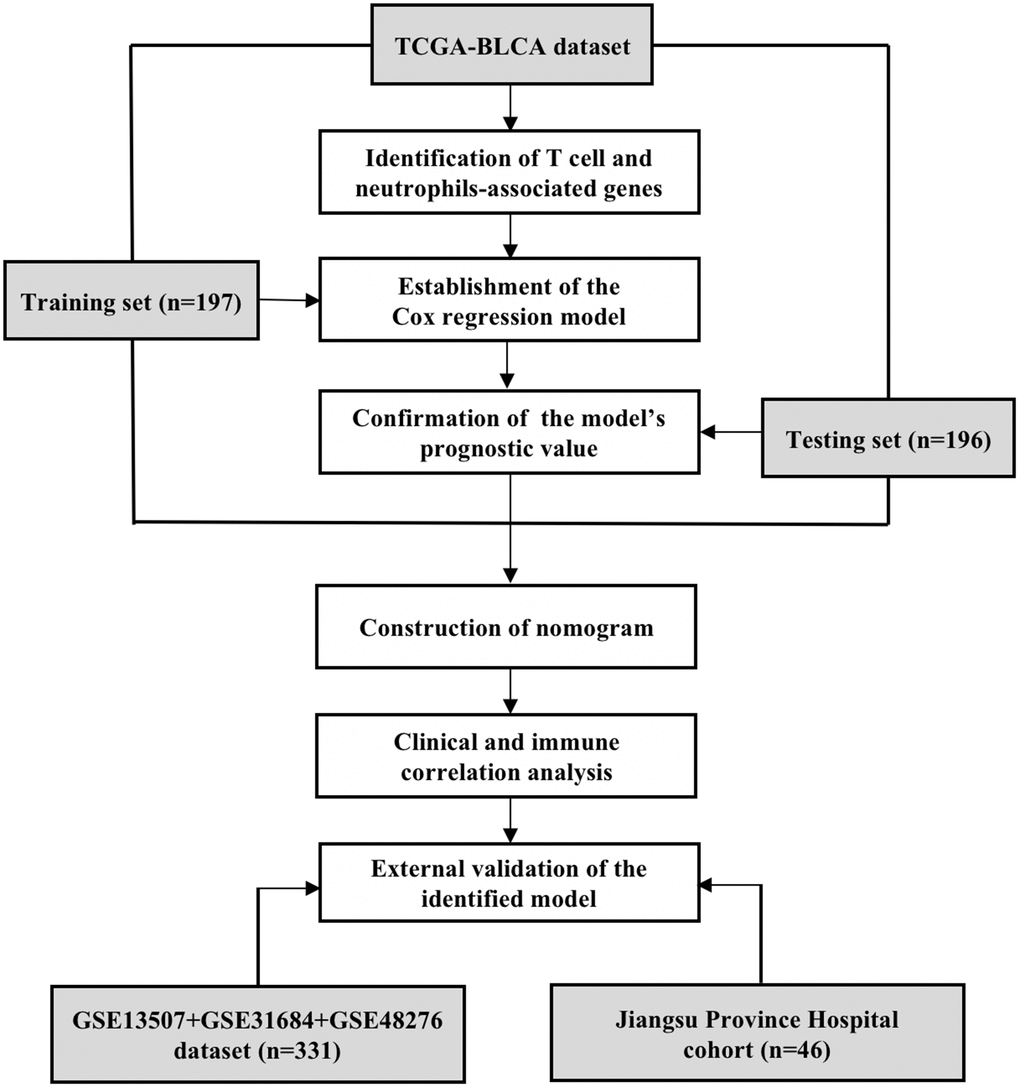
Figure 1.The flow chart of study design. The T cell and neutrophils-associated genes were identified by Spearman correlation analysis using the data of TCGA-BLCA dataset. The total 393 samples of the TCGA-BLCA dataset were then randomly divided into the training and testing sets for the construction and validation of prognostic model. The clinical- and immune-correlation of the identified model was further explored in the whole TCGA-BLCA dataset. Two independent sets, including an integrated GEO dataset and a cohort recruited from the Jiangsu Province Hospital, were further analyzed for the external validation of the model.