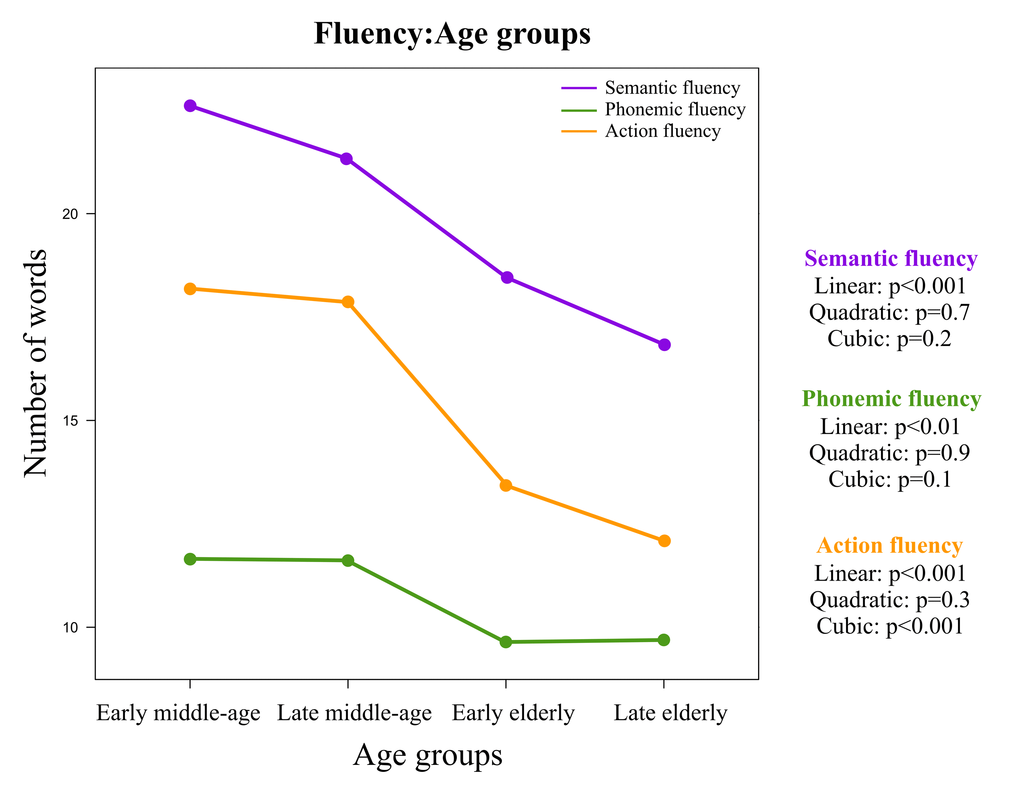
Figure 1.The mixed ANCOVA model for age-related differences on verbal fluency. The x-axis represents the age groups. The y-axis represents the number of words produced. The total number of words produced on phonemic fluency (F+A+S) was divided by three in order to allow comparability among the three fluency modalities (1 minute). P-values are reported for the estimation of linear, quadratic, and cubic effects from the trend analysis tested through the ANCOVA model. The lines represent the outcome from the mixed ANCOVA for age (between-subjects factor) and fluency modality (within-subjects factor) using cross-sectional data.